
End users of large data banks must be protected from knowing how the data is organized in the machine – the internal representation. Generally, most application programs should remain unaffected when the internal representation of data is changed or even when some aspects of the external model are changed.
The guiding principle of Data Virtualization is:
Users and applications should be independent of the physical and logical structure of data
![]()
Data abstraction and decoupling
Companies store a lot of data over different data sources built over time.
These data sources are developed using different technologies and have very different data models, including structured and unstructured data.
In a typical Data warehouse structure, we usually see that the given data is used by two types of people:
- First is the IT guy that does the development of data (IT View)
- Second is the end user that focuses on data only from the business point of view (Business View)
From an IT point of view, we must handle heterogeneous systems that are different schemas, query language, data models, and security mechanisms and must deal with a rapidly changing environment like Business conditions, technology evolution, and infrastructure changes.

The Future of Big Data
With some guidance, you can craft a data platform that is right for your organization’s needs and gets the most return from your data capital.
End users see relationships between the data assets, like whether the models are stable throughout time, business policies are expressed in terms of the model, and end users expect consistent performance.
With the increasing Hi-Data growth, IT complexity, and Hi-Latency, there is an urgent need to decouple these two things. To achieve real-time data and do data analytics, we need to create a layer between them.
So here comes data virtualization.
What is Data Virtualization?
Data virtualization acts as an abstraction layer. It bridges the gap between the complexity of IT teams and the data consumption needs of business users.
Bridging the gap
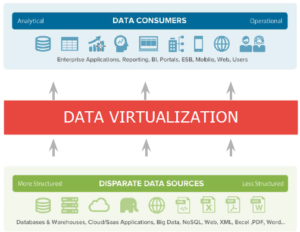
Data virtualization is a logical layer that:
- Delivers business data in real-time to business users
- Connect to disparate data sources and integrates them without replicating the data
- Enables faster access to all data, reduces cost, and is more agile to changes
So, we can define data virtualization as –
“Data virtualization can be used to create virtualized and integrated views of data in-memory rather than executing data movement and physically storing integrated views in a target data structure. It provides a layer of abstraction above the physical implementation of data to simplify query logic.”
What data virtualization is not –
- It is not an ETL tool – ETL tools are designed to replicate data from one point to another.
- It is not data visualization – Data visualization tools are Tableau and Power BI.
- It is not a database – Data virtualization doesn’t store any data
Why Data Virtualization?
Data virtualization is used for the integration of data. But the question arises as to why to use data virtualization for integration when we already have different other concepts like ETL and ESB?
Extract, Transform, and Load (ETL) processes were the first data integration strategies.
In an ETL process, the data is extracted from a source, transformed, and loaded into another data system. This process was very efficient and effective at moving large sets of data. But moving data to another system requires a new repository. And this repository needs to be maintained from time to time. Also, the data stored is not real-time data. The end user must wait until the new data is loaded and ready to use.
So, the key challenges were:
- Timely data
- Available data
- Instant data
- Adaptable data
But data virtualization fixes all these and provides data that is:
- Available
- Integrated
- Consistent
- Correct
- Timely
- Instant
- Documented
- Trusted
- Actionable
- Adaptable
Data virtualization supports a wide variety of sources and targets, which makes it an ideal data integration strategy to complement ETL processes.
Very Informative.