
In the last blog PART1, we discussed Full load with the help of an example in the SSIS (SQL Server Integration Service).
In this blog, we will discuss the concept of Incremental load with the help of the Talend Open Studio ETL Tool.
Incremental Load:
The ETL Incremental Loading technique is a fractional loading method. It reduces the amount of data that you add or change and that may need to be rectified in the event of any irregularity. Because less data is loaded and reviewed, it also takes less time to validate the data and review changes.
Let’s Elaborate this with an Example:
Suppose the file is very large, for example, there are 200m to 500m records to load, it is not possible to load this amount of data in a feasibletime because sometimes we do not havethe required amount of time to load the data during the day.So we have to update the data during night-time and which is limited in terms of hours.. Hence there is a great possibility that the entire amount of data is not loaded.
In scenarios where the actual updated records are very less in number but the overall data size is very huge, we go with the incremental load, or in other words the differential load.
In the incremental load, we figure out how many many records are to be updated to the destination table and how many records in the source file or source table which are new that can be inserted into the destination table. Once this is decided, we just update or insert to the destination table.
How to Perform Incremental Load in Talend ETL?
Incremental loading with Talend can be done like in any other ETL tool. You must measure in your job the necessary time stamps of sequence values and keep the highest value for the next run and use this value in a query where the condition is to start reading all rows with this higher value.
Incremental loading is a way to update a data set with new data. It can be done by replacing or adding records in a table or partition of a database.
There are different ways to perform an incremental load in Talend ETL:
1) Incremental Load on New File: This method updates the existing data set with new data from an external file. This is done by importing the new data from the external file and overwriting the existing records.
2) Incremental Load on Existing File: This method updates the existing data set with new data from another source, such as a database table. In this case, records from both sources are merged and updated in one go.
3) The source database may have date time fields that may help us identify which source records got updated. Using the context variable and audit control table features, we can retrieve only the newly inserted or updated records from the source database.
Now you all know what Incremental Load in ETL is, Let’s Explore this using the Talend Open Studio.
Source Table:
We have a source table Product_Details with created_on and modified_on columns. Also, we have some existing data in the table.

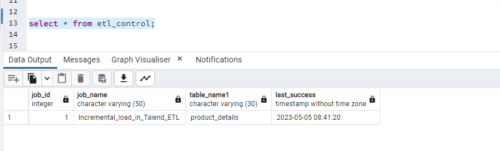
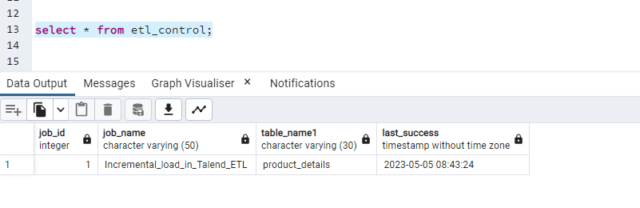
ETL Control Table:
By using the etl_control table we will capture the last time when the job was successful. When we have 100 jobs and tables. We don’t want to keep it in different places it is always good practice to keep one etl_control table. In which we will capture the particular job name, table name, and last success as when it was last loaded.
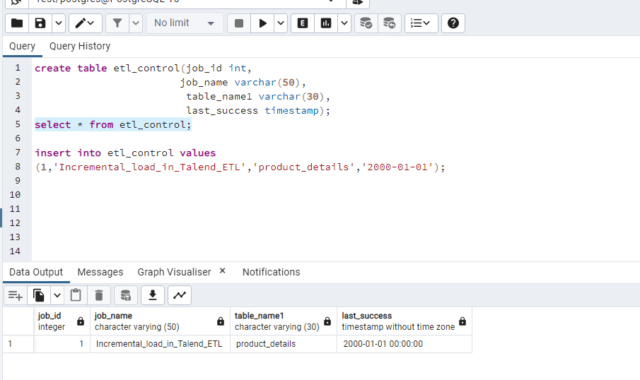
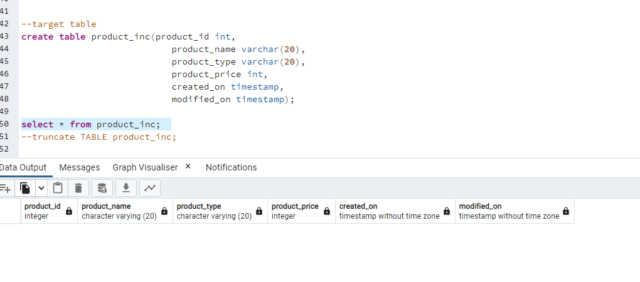
Target Table:
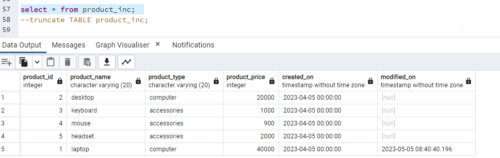
Product_inc is our target table. In the ETL Control table, we will give a last success date older than the source table and we will give conditions on the basis of the created_on column to insert and update data in the target table Product_inc.
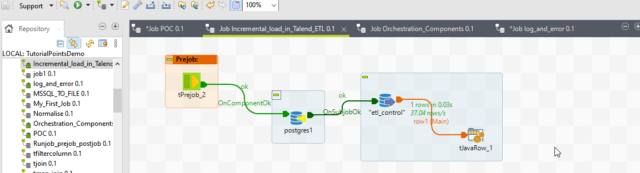
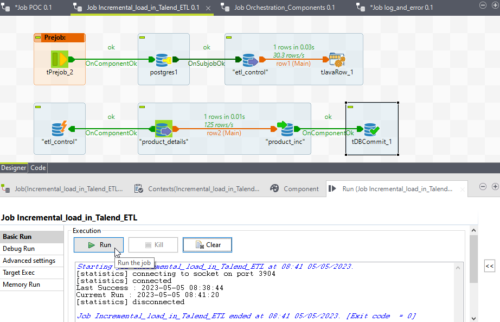
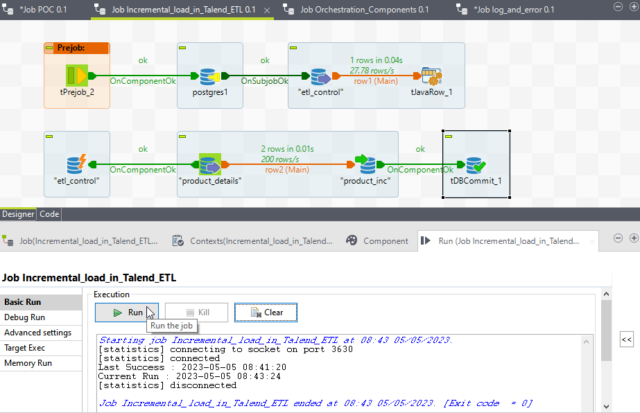
Now we will Explore our Talend job.
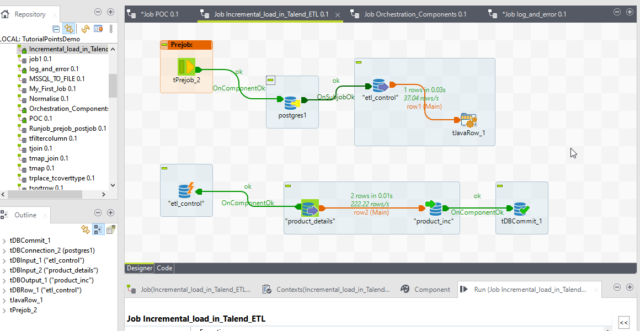
First, we will drag and drop tDBConnection for our Postgres SQL connection. So, we can use this connection multiple times in the job. hen we will import all the tables.
Now we drag the etl_control table as input where we are saving the last success timestamp for a particular job.
Then we will drag and drop the tJavaRow component. With the help of this component, we will set the value for the last success timestamp. We write a Java code as below.

To store those values, we will create two context variables last_success timestamp and current_run. Timestamp.
- Last_success will be used to retrieve the data from the source.
- Current_run will be used to update the etl_control back when the job was successful.
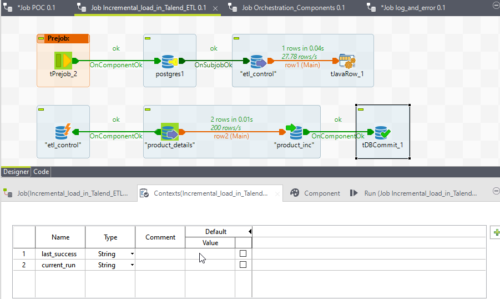
Now we drag and drop the tPreJob component ensures that the below steps are always executed before the sub-job execution.

The Future of Big Data
With some guidance, you can craft a data platform that is right for your organization’s needs and gets the most return from your data capital.
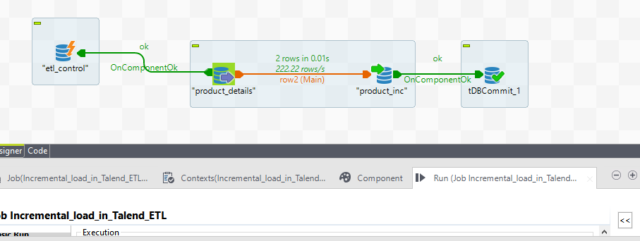
Next we add the actual source and target table to create the Sub-Job. Also, we drag the etl_control table as a tDBRow component to update back etl_control table.
It is connected with OnSubJobOk with the source table. So, if the job fails for any reason so it will not update back etl_control table because in the next run or the next day run the same records will be processed from the point it was processed last time.
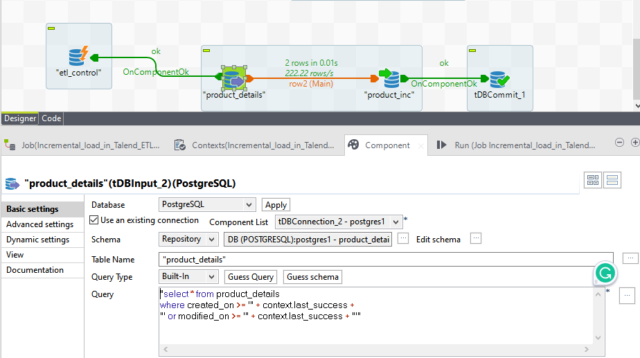
Input Component:
We change the existing query which is selecting all the column’s data with no condition.
For incremental load, we provide filter conditions so it will select newly inserted rows and updated values from the last run of the job.
“select * from product_details
where created_on >= ‘” + context.last_success +
“‘ or modified_on >= ‘” + context.last_success + “‘”
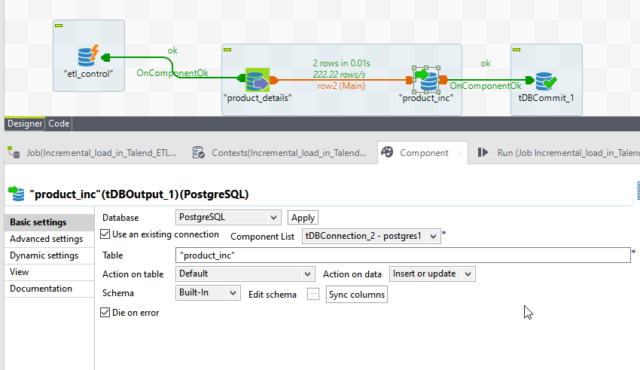
Output Component:
In the target table, we will modify in Action on Data to Insert and Update for the table
Based on the key value so in the edit schema we will provide the key value in the target table to product_id.
Control Component:
We will add an update command to update the etl_control table.
“Update etl_control set last_success = ‘”
+ context.current_run+
“‘ where job_name = ‘” + jobName + “‘”
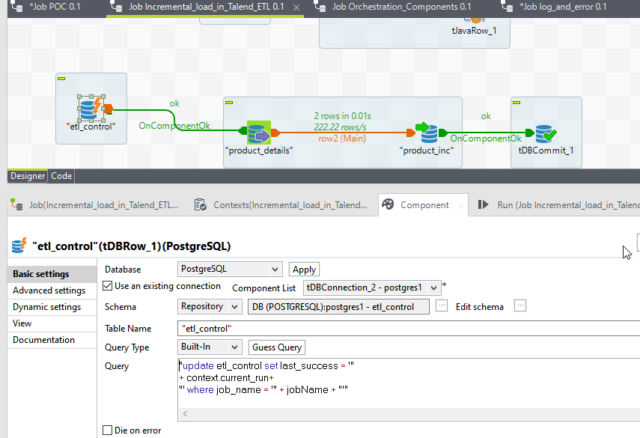
This update command will dynamically update the last_success timestamp with a timestamp of the job run time. If we have multiple jobs so for a particular job, we also provided a condition where we used the global variable jobName to update the particular job’s last_success time stamp.
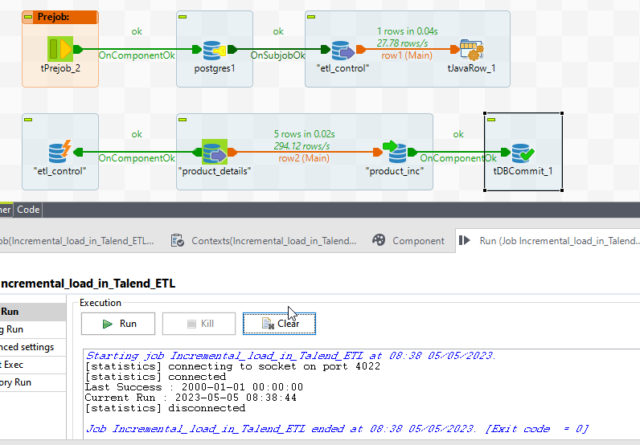
RUN1:
Now save the job and run it. We can see we read one record from the etl_control table and inserted 5 rows in the target table.
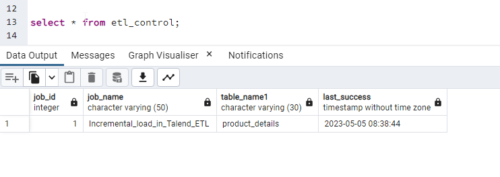
In the etl_control table based on the job name; it will update the last_success timestamp with the job run timestamp.

If we rerun the job without any changes, it will not process any record in the sub-job present in the source table.
RUN2:
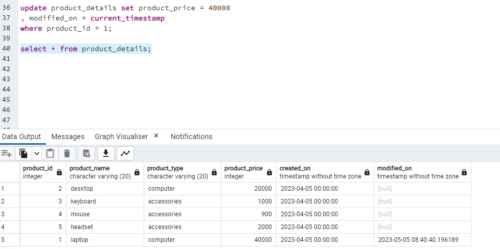
Now we will update one of the values in the source table and then run the job again.
It will capture only one record that is updated based on the last successful run time.
RUN3:
Now, we will insert one new record and update one of the existing values and then run the job again.
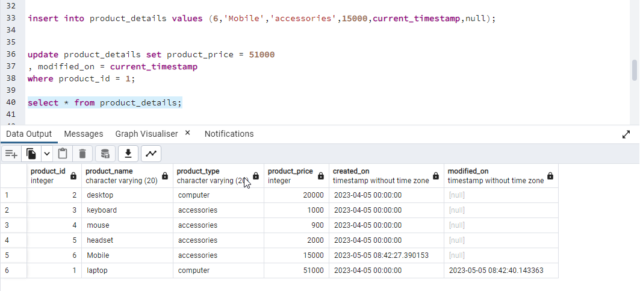
We can see two records from which one is a newly inserted record, and one is an updated record.
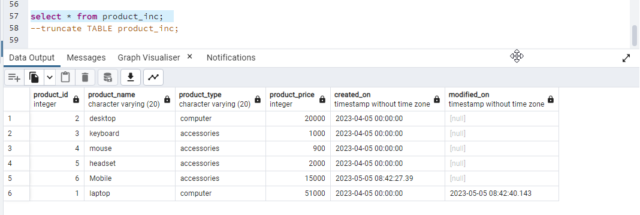
So, this is how incremental load works based on the last successful run time to the start of the job to pick up inserted or updated records.
Please share your thoughts and suggestions in the space below, and I’ll do my best to respond to all of them as time allows.
For more such blogs click here
Happy Reading!
This is a fantastic idea, especially for new readers. Thank you for sharing this information, which is brief but quite precise. A must-read article!