
In data engineering and analytics workflows, merging files emerges as a common task when managing large datasets distributed across multiple files. Databricks, furnishing a powerful platform for processing big data, prominently employs Scala. In this blog post, we’ll delve into how to merge files efficiently using Scala on Databricks.
Introduction:
Merging files entails combining the contents of multiple files into a single file or dataset. This operation proves necessary for various reasons, such as data aggregation, data cleaning, or preparing data for analysis. Databricks streamlines this task by providing a distributed computing environment conducive to processing large datasets using Scala.
Prerequisites:
Before embarking on the process, ensure you have access to a Databricks workspace, and a cluster configured with Scala support. Additionally, you should have some files stored in a location accessible from your Databricks cluster.
Let’s explore the Merging through an example:
In the below example we have three files – a header file, a detail file and a trailer file which we will be merging using Databricks Spark Scala.
The Header file needs to be written first followed by the Detail File and the Trailer file.
Preparing up the files:
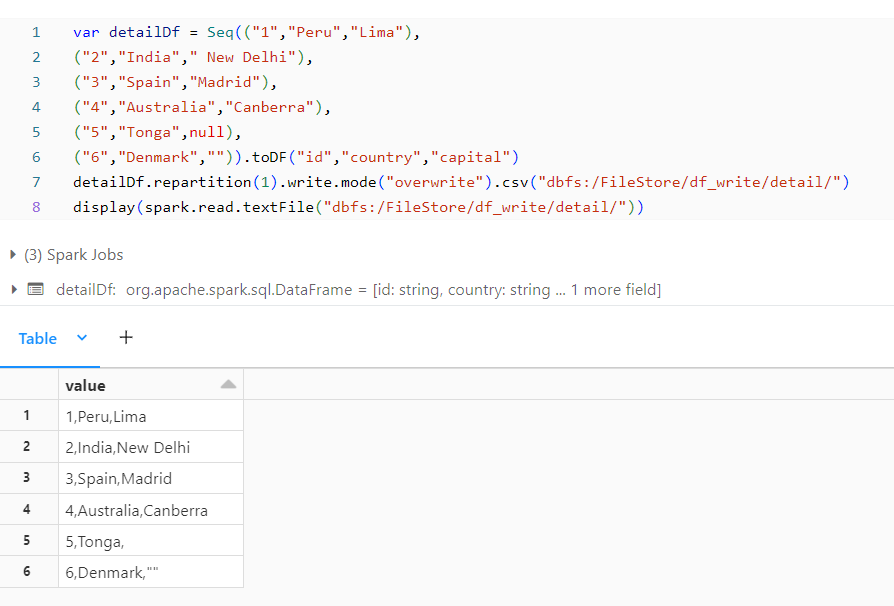
Detail File:
The Detail File contains the major data of the file here in this case it contains the Country and its corresponding capitals.
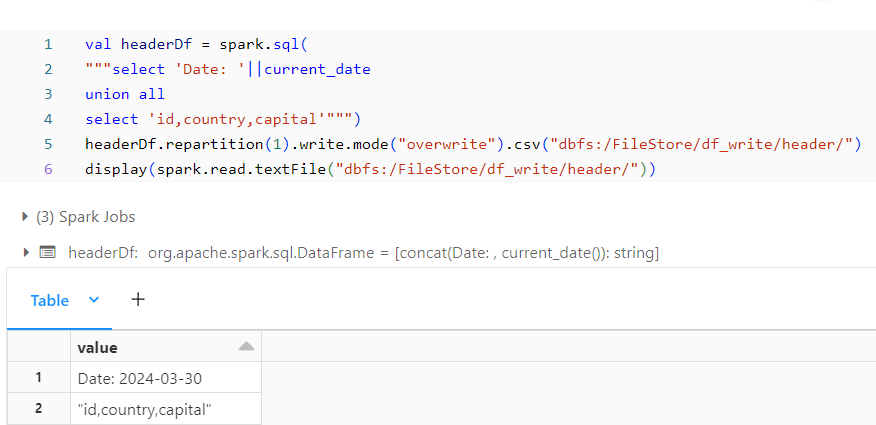
Header File:
Header File contains the Name of what kind of file, sometimes date when the file is generated and the header for the content in the detail file.
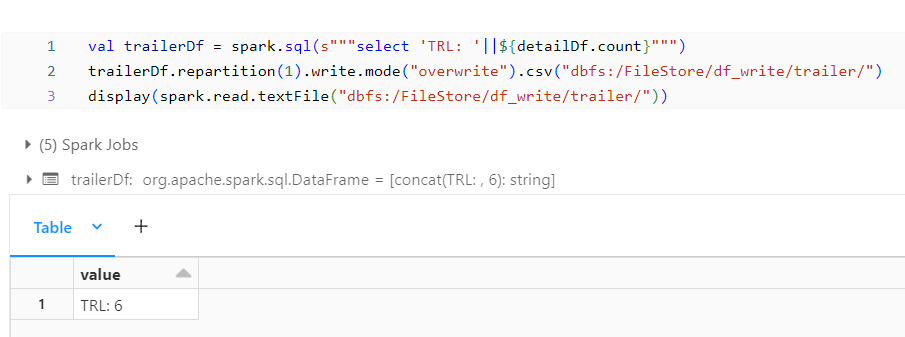
Trailer File:
Trailer File often contains the count of the rows present in the Detail File.
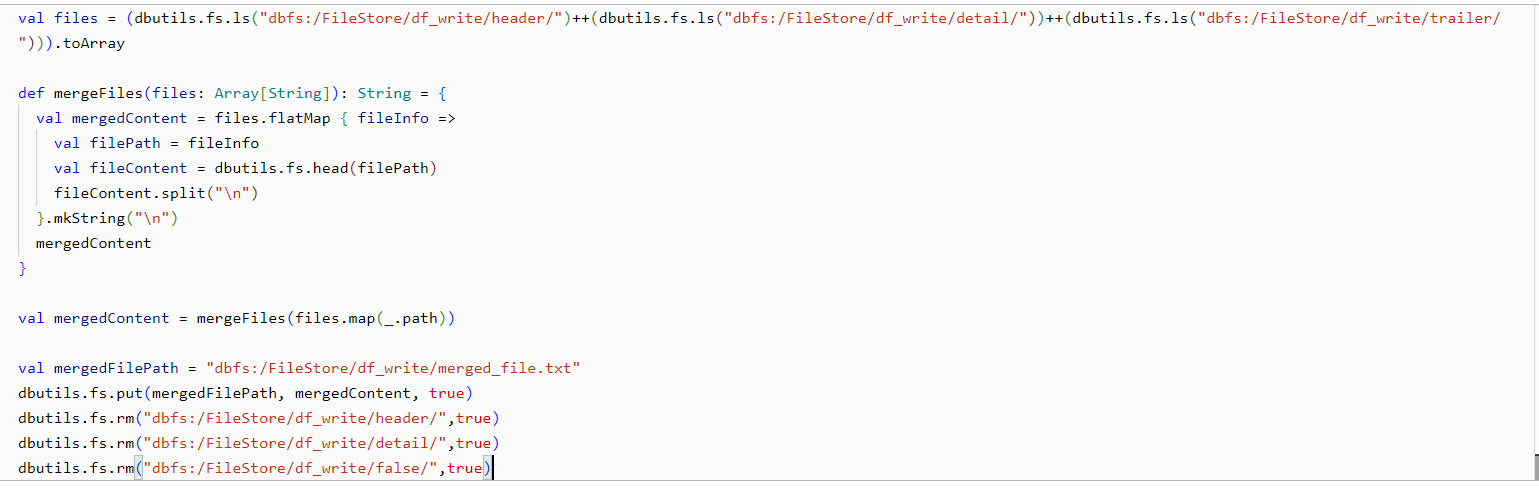
Merging Approach:
We will be reading the files in the appropriate order and then write them into a single file. At the last we need to remove the files which we have used which is a good approach.
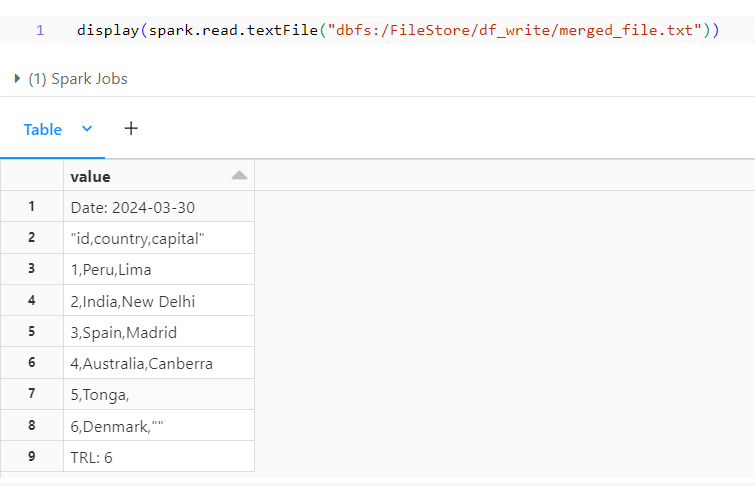
Merged File:
Below is the output merged file were all the header, detail and trailer are displayed in the order.
References:
Check out the blog on writing into DataFrame here: and Using DBFS here : DBFS (Databricks File System) in Apache Spark / Blogs / Perficient
Check out more about Databricks here: Databricks documentation | Databricks on AWS
Conclusion:
Effectively merging files is pivotal for data processing tasks, especially when grappling with large datasets. In this blog post, we’ve elucidated how to merge files using Scala on Databricks through both sequential and parallel approaches. Depending on your specific use case and the size of your dataset, you can opt for the method best suited to merge files efficiently. Databricks’ distributed computing capabilities, coupled with Scala’s flexibility, render it a potent combination for handling big data tasks.


