
This blog post explores how to write Spark DataFrame into various file formats for saving data to external storage for further analysis or sharing.
Before diving into this blog have a look at my other blog posts discussing about creating the DataFrame and manipulating the DataFrame along with writing a DataFrame into tables and views.
- Creating DataFrame: https://blogs.perficient.com/2024/01/10/spark-scala-approaches-toward-creating-dataframe/
- Manipulating DataFrame: https://blogs.perficient.com/2024/02/15/spark-dataframe-basic-methods/
- Writing DataFrame into Tables and Views: Spark DataFrame: Writing to Tables and Creating Views / Blogs (perficient.com)
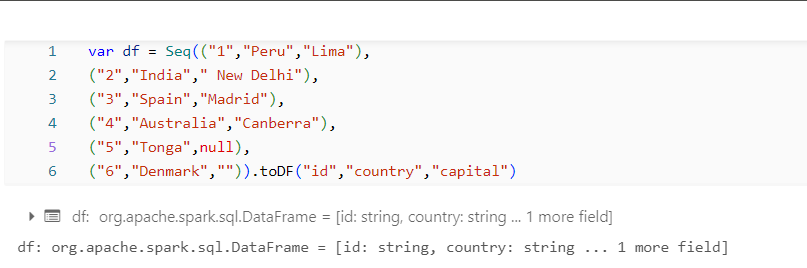
Dataset:
The Below is the Dataset that we will be using for looking on writing into a file from DataFrame.
Writing Spark DataFrame to File:
CSV Format:
Below is the Syntax to write a Spark DataFrame into a csv.
df.write.csv("output_path")
Lets go over writing the DataFrame to File using examples and scenarios.
Example:
The below snapshot is the sample for writing a DataFrame into a File.
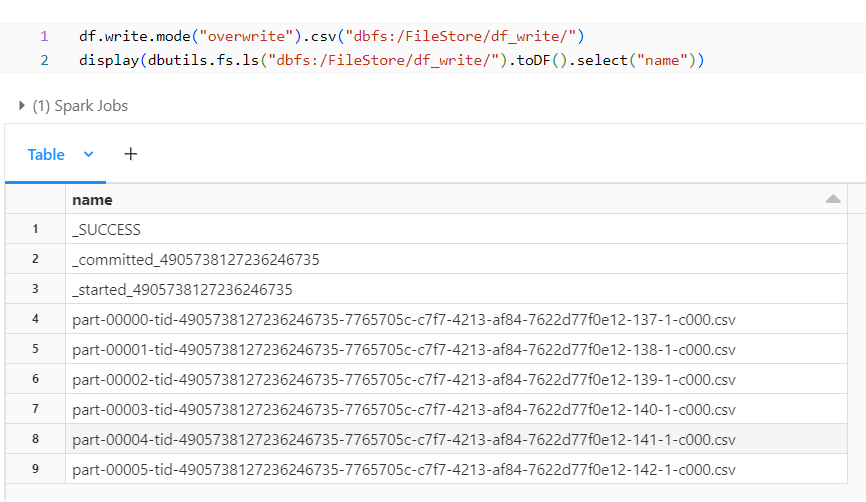
After writing the DataFrame into the path, the files in the path are displayed. The displayed Part Files are the ones where the data is loaded. Databricks automatically partitioned each row into a file and created a file for all of the rows. We can repartition and create a single file from the DataFrame.
DataFrame Repartition:
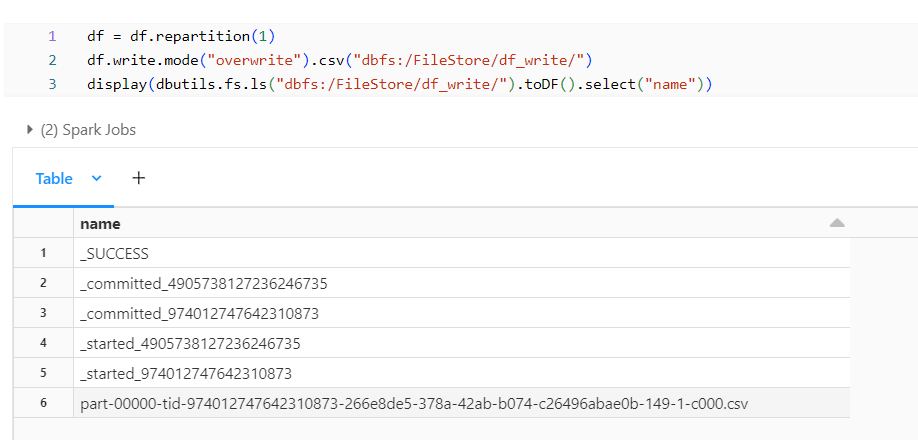
After repartitioning, we observe that all the part files combine into a single file, and we notice other files besides the part files, which we can ignore from creating by using some Spark configurations below. These files will be created even when writing the data into other file formats rather than csv.
Removing _committed and _started Files:
We can use the below spark configuration which will not create the files starting with _commited and _started. =
spark.conf.set("spark.sql.sources.commitProtocolClass", "org.apache.spark.sql.execution.datasources.SQLHadoopMapReduceCommitProtocol")
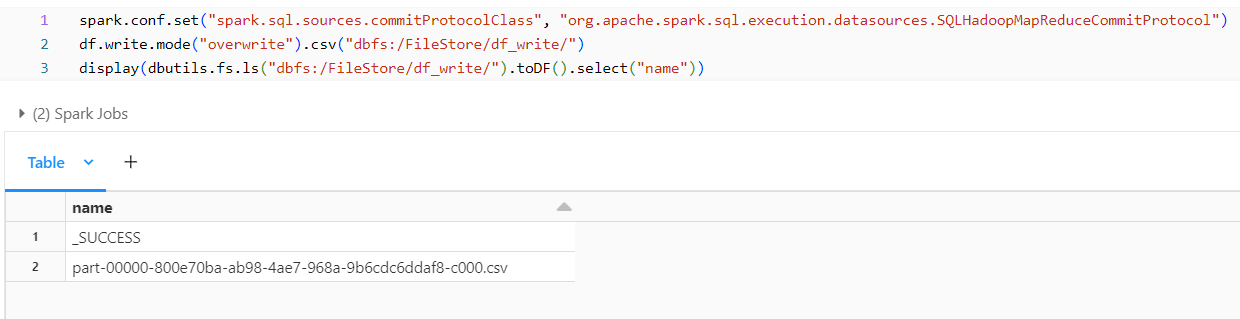
Removing _SUCCESS File:
We can use the below spark configuration to stop the _SUCCESS file from getting generated.
spark.conf.set("mapreduce.fileoutputcommitter.marksuccessfuljobs", "false")
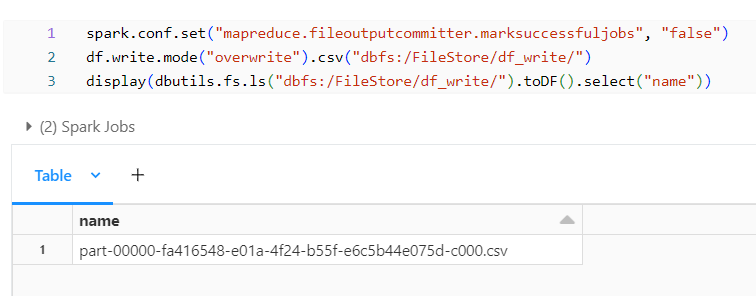
Data in the File:
With all the additional files removed we can see the data present within what is being loaded into the file. We can notice that by default spark doesn’t write header into the files we can modify them by using option/options. In addition, let’s see the available options when writing a DataFrame into a file.
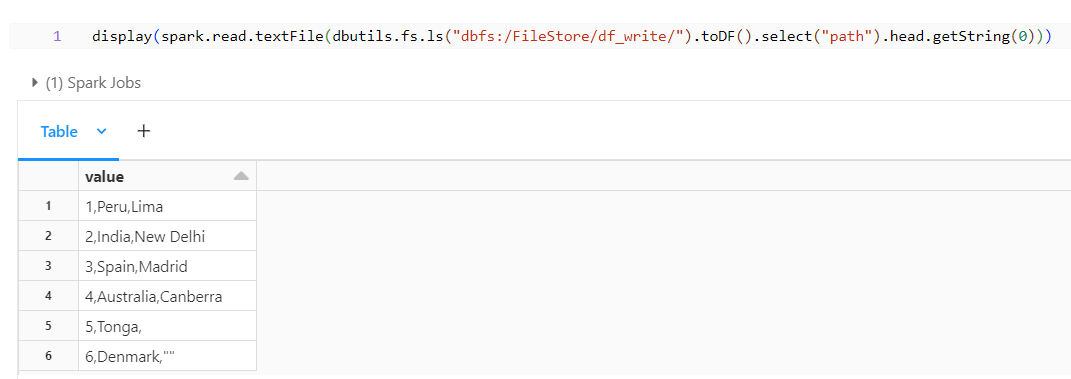
Header Option:
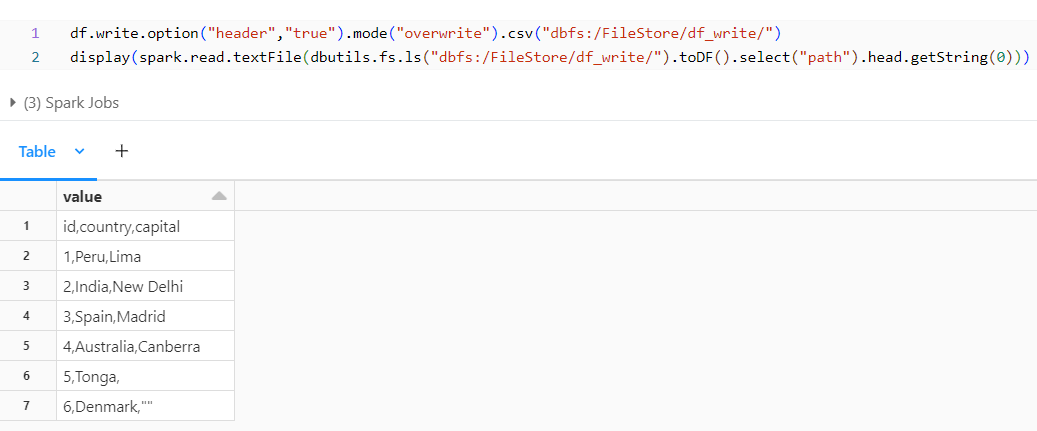
By adding the header option, we observe that the header is populated in the file. Similarly, we have a option to change the delimiter.
Delimiter Option:
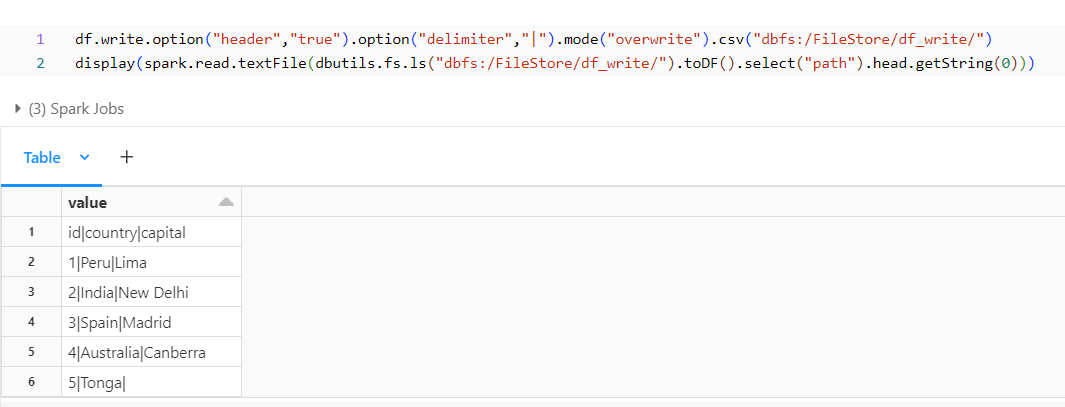
We can change the delimiter to our desired format by adding the additional option – delimiter or we can also use sep (syntax provided below).
df.write.option("header","true").option("sep","|").mode("overwrite").csv("dbfs:/FileStore/df_write/")
nullValue Option:
From the previous output we can notice that the Capital for Tonga in the DataFrame is null though in the csv it would have populated as empty. We can have it retained as null by using the nullValue option.
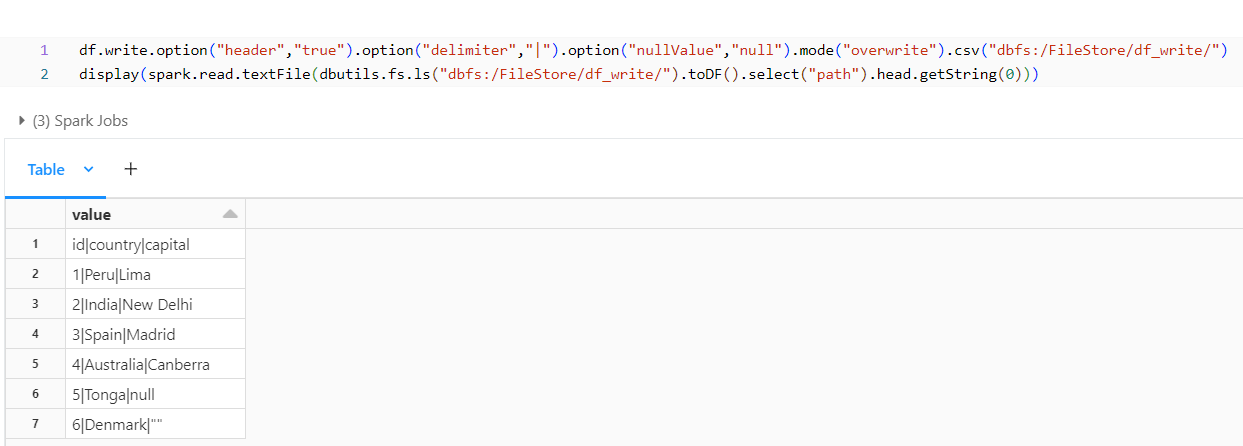
With this option, we observe that null is retained.
emptyValue Option:
In some scenarios we may need to populate null for empty values, in that case we can use the below option.
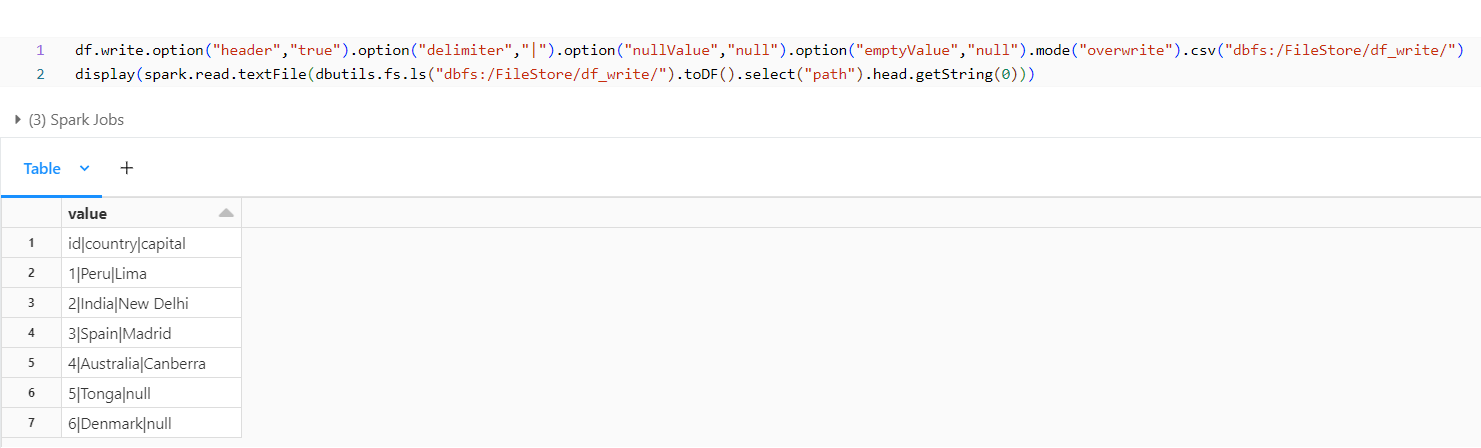
From the output above, we observe that Denmark previously had an empty value populated for its capital, but it is now being populated with null.
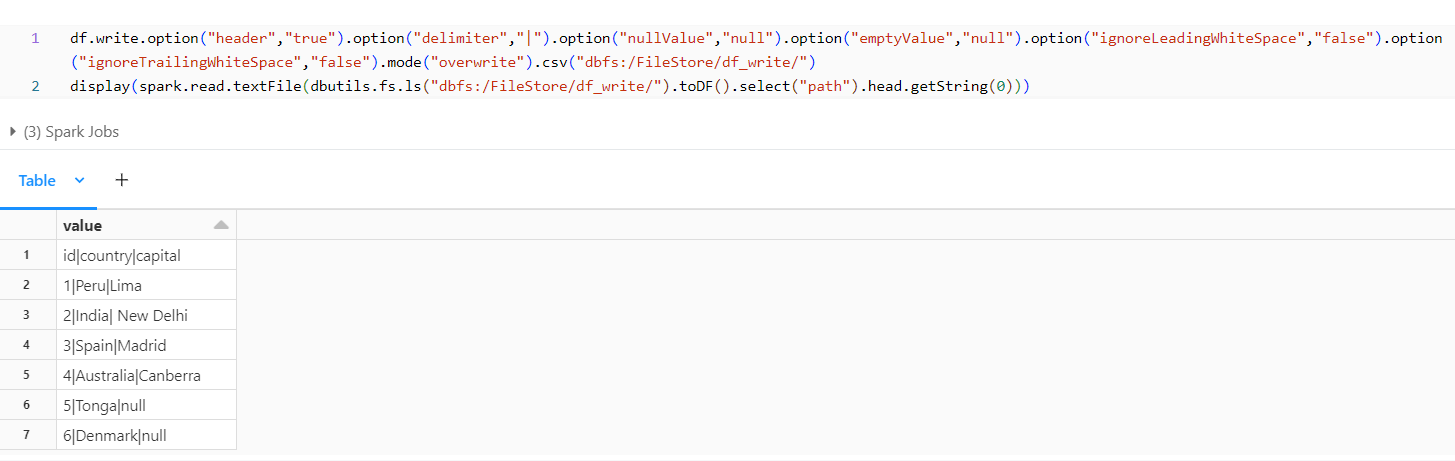
ignoreLeadingWhiteSpaces and ignoreTrailingWhiteSpaces Option:
If we need to retain the spaces before or after the value in a column, we can use the below options.
Different Way to use Multiple Options:
We can have all the options for the file format in a common variable and then use it whenever needed if we have to use the same set of options for multiple files.
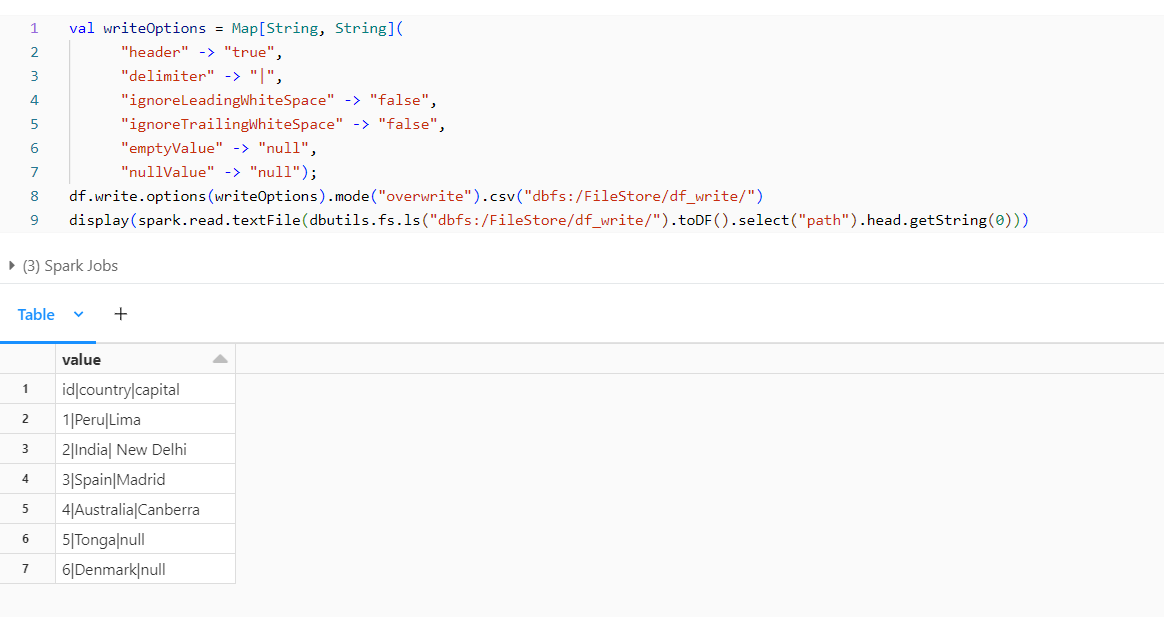
We have created a variable writeOptions of Map type which has the options stored within it and we can use it whenever we need that Output Option.
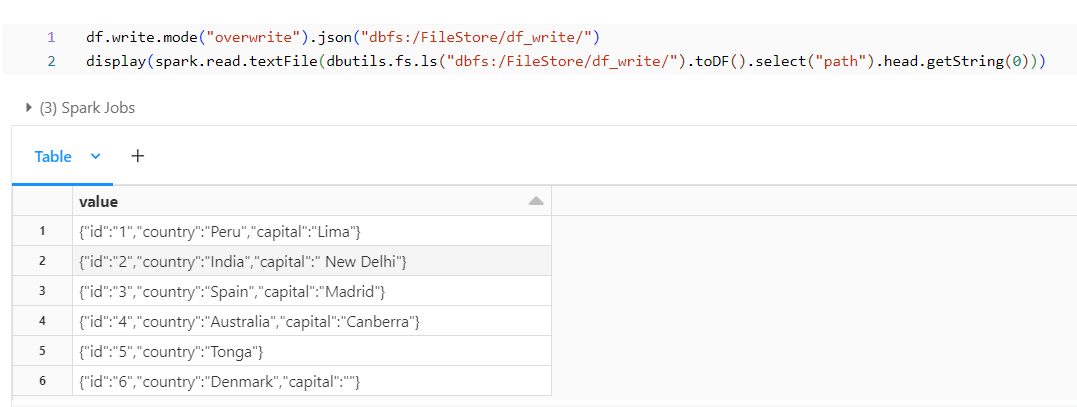
JSON Format:
We can use the below syntax and format to write into a JSON file from the DataFrame.
Other Formats:
ORC Format:
Below is the syntax for writing the DataFrame in ORC Format:
df.write.mode("overwrite").orc("dbfs:/FileStore/df_write/")
Parquet Format:
Below is the syntax for writing the DataFrame in ORC Format:
df.write.mode("overwrite").parquet("dbfs:/FileStore/df_write/")
Similar to the above there are several more formats and examples along with syntaxes which you can reference from the below links.
- https://spark.apache.org/docs/latest/api/java/org/apache/spark/sql/DataFrameWriter.html
- https://spark.apache.org/docs/latest/sql-data-sources-load-save-functions.html
- Tutorial: Load and transform data with Apache Spark Scala DataFrames | Databricks on AWS
In this blog post, we covered the basics of writing Spark DataFrame into different file formats. Depending on your specific requirements and use cases, you can choose the appropriate file format and configuration options to optimize performance and compatibility.


