
In this Blog Post we will see methods of writing Spark DataFrame into tables and creating views, for essential tasks for data processing and analysis.
Before diving into this blog have a look at my other blog posts discussing about creating the DataFrame and manipulating the DataFrame.
- Creating DataFrame: https://blogs.perficient.com/2024/01/10/spark-scala-approaches-toward-creating-dataframe/
- Manipulating DataFrame: https://blogs.perficient.com/2024/02/15/spark-dataframe-basic-methods/
Dataset:
The Below is the Dataset that we will be using for looking on writing into a table and create views from DataFrame.

Writing DataFrame to Tables:
Writing into Table allows us to run SQL queries against the data and perform more complex analyses. Spark supports various storage formats such as Parquet, ORC, and Delta Lake for persisting DataFrames.
insertInto:
df.write.insertInto("table")
Above code block is a sample for writing a DataFrame into a table. We need to have write method mentioning that we are going to write the DataFrame and then insertInto method to write into a Table.
Overwrite:
By Default, insertInto method uses append mode to load the data into a Table. We can modify the load mode by calling out .mode method. Within that we can mention overwrite to truncate and reload the data from the new df.
df.write.mode("overwrite").insertInto("table")
JDBC:
The above insertInto method only works for inserting into the internal database in the above case it is Databricks. Whereas we can use JDBC connection to load the DataFrame into external database. The below is the syntax for writing DataFrame using JDBC.
df.write
.format("jdbc")
.option("url", "jdbc:postgresql:dbserver")
.option("dbtable", "schema.tablename")
.option("user", "username")
.option("password", "password")
.save()
saveAsTable:
insertInto method can be used when writing into an existing table, whereas saveAsTable can be used to create a new Table out of the DataFrame.
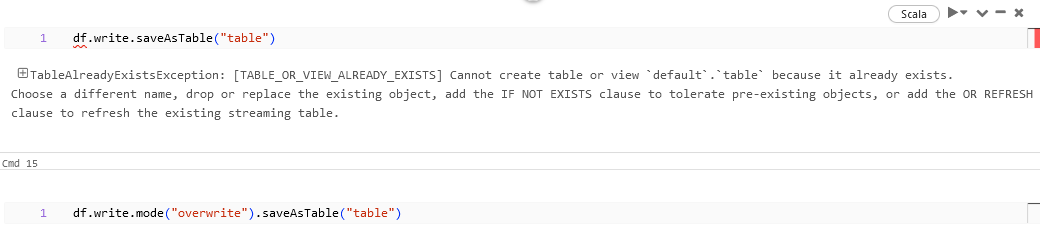
df.write.saveAsTable("table")
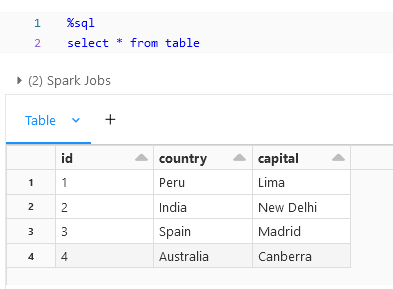
The Above is the result from writing the DataFrame into a Table and reading through SQL.
saveAsTable Overwrite:
When trying to use saveAsTable with an existing table then we might end up with the exception stating that the table is already existing. In this case .mode(“overwrite”) can be used to overwrite the existing table with the new DataFrame.
Creating Views from DataFrame:
In addition to persisting DataFrames as tables, we can create temporary views that exist only for the duration of the SparkSession. Temporary views are useful for running SQL queries without the need to persist data permanently.
Spark createTempView:
Below is the syntax for creating a temporary view out of a DataFrame.
df.createTempView("view")
Spark createOrReplaceTempView:
Similar to saveAsTable if we use the same view name for two create views we will be getting exception that the Temp Table is already existing.
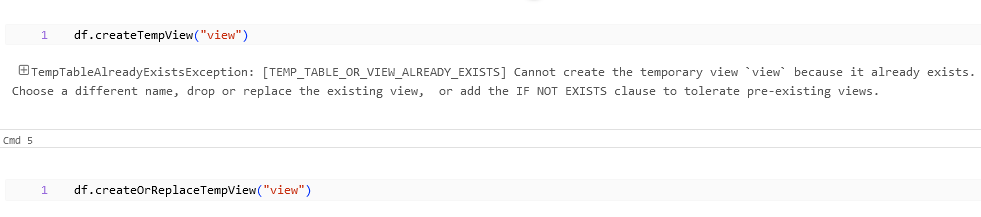
For this case we can use createOrReplaceTempView instead of createTempView which will replace the existing view with the data from the new DataFrame.
Spark createGlobalTempView:
This method creates a temporary view that is global-scoped. It means the view will exist across all sessions and even after the Spark application that created it has terminated.
df.createGlobalTempView("global_view")
Similar to createOrReplaceTempView Global view also have similar syntax to replace the Global Temp View.
df.createOrReplaceGlobalTempView("global_view")
References:
Below are the Spark Documents exploring more on writing the DataFrame into Tables and Views.
- https://spark.apache.org/docs/latest/api/java/org/apache/spark/sql/DataFrameWriter.html
- https://spark.apache.org/docs/latest/sql-data-sources-load-save-functions.html
- https://spark.apache.org/docs/latest/sql-data-sources-jdbc.html
In this blog post we learnt how to write DataFrames to tables using different storage formats and create temporary views for ad-hoc analysis.



