
Apache Spark is a powerful open-source distributed computing system widely used for big data processing and analytics. When working with structured data, one common challenge is dealing with parsing errors—malformed or corrupted records that can hinder data processing. Spark provides flexibility in handling these issues through parser modes, allowing users to choose the behavior that best suits their requirements. In this blog post, we’ll delve into three key parser modes: FailFast, Permissive, and Drop Malformed.
Different Spark Parse Modes:
FailFast Mode:
FailFast is a parser mode in which Spark adopts a strict approach. If any parsing error is encountered while reading data, Spark immediately halts the process and raises an exception. This mode is ideal when data integrity is paramount, and you prefer to avoid processing any data with potential issues.
val dfFailFast = spark.read.option("mode","FAILFAST").csv(filePath)
Permissive Mode:
Permissive mode, Spark takes a more lenient approach. It attempts to parse and load as much data as possible, even if some records are malformed. Parsing errors are logged, but Spark continues processing the rest of the data. This mode is suitable when you want to salvage valid data while being aware of parsing issues. If there is malformed data, then the record will be loaded as null.
val dfPermissive = spark.read.option("mode","PERMISSIVE").csv(filePath)
Drop Malformed Mode:
Drop Malformed mode is another option for handling parsing errors. In this mode, Spark skips and drops any records that cannot be parsed correctly. It processes only the valid records while discarding the malformed ones. If your goal is to focus on processing clean and error-free data, Drop Malformed mode is a pragmatic choice. Even if there is a particular column that has malformed data the entire row will be dropped.
val dfDropMalformed = spark.read.option("mode","DROPMALFORMED").csv(filePath)
Let’s these Spark Parser modes with examples:
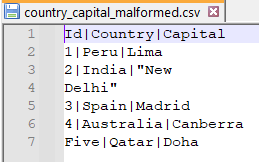
Dataset Used:

Schema:

As we can infer from seeing the file and the Schema that we have defined the datatype for the column Id is integer whereas in the source file for Qatar the Id is string for which we will see how different spark parser modes work.
Permissive:
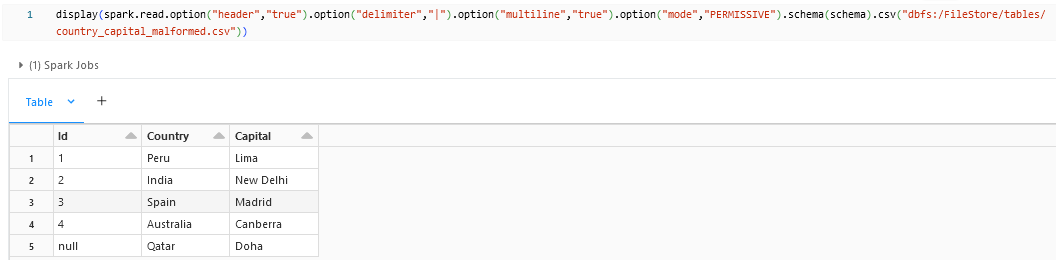
When using the Permissive parser mode, we can see that the column Id for Qatar is loaded as null. The Permissive mode will allow the malformed record to flow through and stores that record as null.
Drop Malformed:
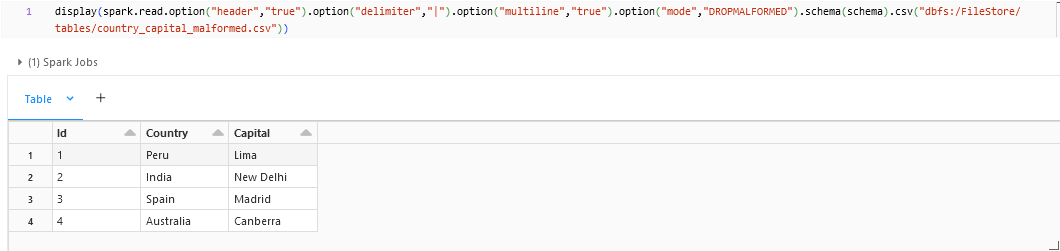
On using the Drop Malformed parser mode, we can see that the malformed column is dropped.
Fail Fast:

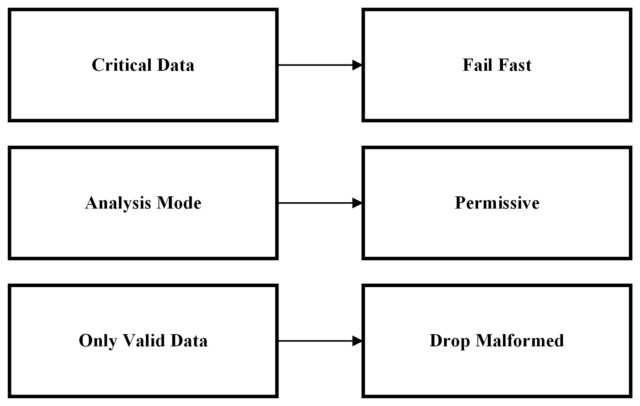
Fail Fast can be used when we have critical data to be processed in this case there will be an exception thrown showing that the record is malformed. As we can see from the above example, we are getting a NumberFormatException where we are trying to load a String into an Integer Column.
Choosing the Right Spark Parser Mode for Your Use Case:
The choice of parser mode depends on your specific use case and data processing requirements.
- FailFast is suitable when you prioritize data integrity and wish to halt processing upon encountering any parsing issues.
- Permissive is beneficial when you want to maximize data processing and salvage as much valid data as possible, even with some parsing errors.
- Drop Malformed is appropriate when you prefer to work with only clean, error-free data and are willing to sacrifice records with parsing issues.
Conclusion:
Understanding Spark parser modes – FailFast, Permissive, and Drop Malformed—provides valuable insights into how Apache Spark handles parsing errors during data processing. By choosing the appropriate mode based on your use case, you can strike a balance between data integrity and the volume of processed data. As always, it’s essential to stay informed about the latest features and best practices, so be sure to check the official Apache Spark documentation for any updates beyond the information presented here.



