
In Apache Spark, DataFrame joins are operations that allow you to combine two DataFrames based on a common column or set of columns. Join operations are fundamental for data analysis and manipulation, particularly when dealing with distributed and large-scale datasets. Spark provides a rich set of APIs for performing various types of DataFrame joins.
Import necessary libraries:
import org.apache.spark.sql.{SparkSession, DataFrame}
import org.apache.spark.sql.functions._
Example:
Consider two DataFrames, employees and departments, which contain information about employees and their respective departments:
import org.apache.spark.sql.{SparkSession, DataFrame}
// Creating a Spark Session
val spark = SparkSession.builder.appName("SparkSQLJoinsExample").getOrCreate()
// Sample data for employees
val employeesData = Seq(
(1, "John", 100),
(2, "Jack", 200),
(3, "Ram", 100),
(4, "Smith", 300)
)
// Sample data for departments
val departmentsData = Seq(
(100, "HR"),
(200, "Engineering"),
(300, "Finance")
)
// Defining schema for employees
val employeesSchema = List("emp_id", "emp_name", "dept_id")
val employeesDF: DataFrame = spark.createDataFrame(employeesData).toDF(employeesSchema: _*)
// Defining schema for departments
val departmentsSchema = List("dept_id", "dept_name")
val departmentsDF: DataFrame = spark.createDataFrame(departmentsData).toDF(departmentsSchema: _*)
Here are the common types of DataFrame joins in Spark:
-
Inner Join:
- Combines rows from both DataFrames where the values in the specified columns match.
- The resulting DataFrame contains only the rows that have matching values in both DataFrames.
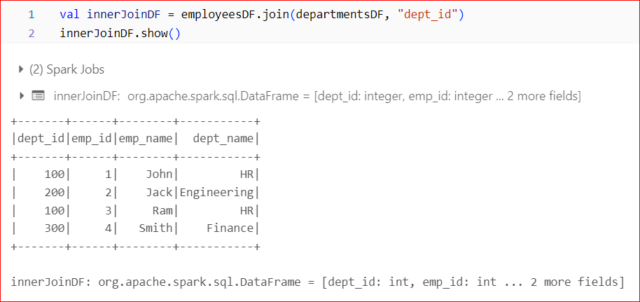
Syntax:
val resultDF = df1.join(df2, “commonColumn”)
 Example:
Example:

-
Left Outer Join:
- Returns all rows from the left DataFrame and the matching rows from the right DataFrame.
- If there is no match in the right DataFrame, null values are included in the result.
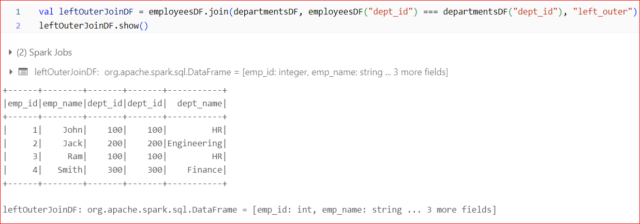
Syntax:
val resultDF = df1.join(df2, “commonColumn”, “left_outer”)
 Example:
Example:
-
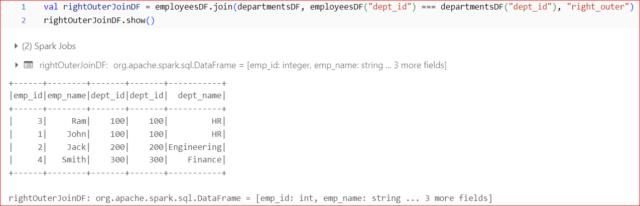
Right Outer Join:
- Returns all rows from the right DataFrame and the matching rows from the left DataFrame.
- If there is no match in the left DataFrame, null values are included in the result.
Syntax:
val resultDF = df1.join(df2, “commonColumn”, “right_outer”)
 Example:
Example:
-
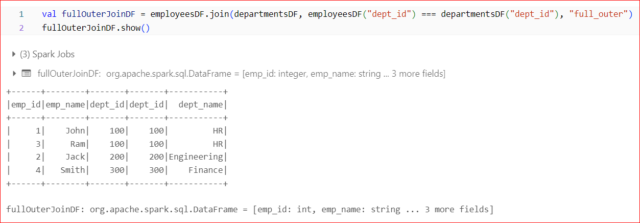
Full Outer Join:
- Returns all rows if there is a match in either the left or right DataFrame.
- If there is no match in one of the DataFrames, null values are included in the result.
Syntax:
val resultDF = df1.join(df2, “commonColumn”, “full_outer”)
 Example:
Example:
-
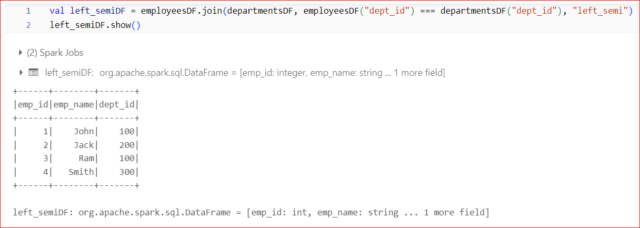
Left Semi Join:
- Returns only the rows from the left DataFrame where there is a match in the right DataFrame.
- It doesn’t include any columns from the right DataFrame in the result.
Syntax:
val resultDF = df1.join(df2, “commonColumn”, “left_semi”)
 Example:
Example:
-
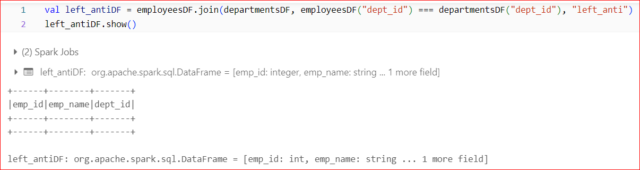
Left Anti Join:
- Returns only the rows from the left DataFrame where there is no match in the right DataFrame.
- It doesn’t include any columns from the right DataFrame in the result.
Syntax:
val resultDF = df1.join(df2, “commonColumn”, “left_anti”)
 Example:
Example:
-
Cross Join:
- Returns the Cartesian product of both DataFrames, resulting in all possible combinations of rows.
- It can be computationally expensive for large datasets.
Syntax:
val resultDF = df1.crossJoin(df2)
 Example:
Example:
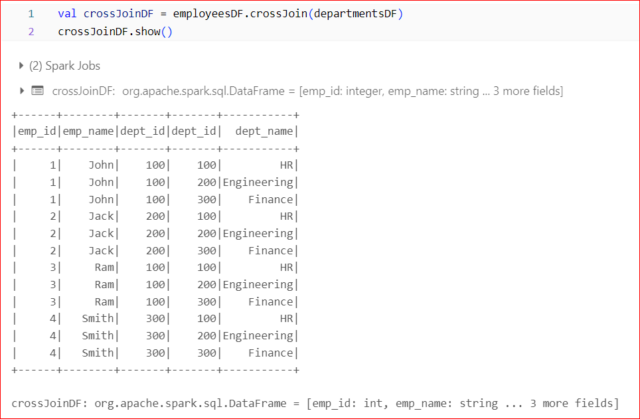
These examples illustrate the basic syntax and functionality of Spark Scala SQL joins. In each case, replace commonColumn with the actual column(s) you want to use for the join. Depending on the use case, you can choose the appropriate type of join to combine and analyze your data effectively in a distributed computing environment.
Conclusion:
DataFrame joins Apache Spark represent a foundational aspect of data analysis and manipulation, particularly in distributed and large-scale environments. These operations facilitate the merging of datasets based on common columns or specified criteria, enabling seamless integration of data for various analytical tasks. With Spark’s rich set of APIs tailored for DataFrame joins, users have the flexibility to execute diverse join operations efficiently. Whether it’s merging disparate datasets or performing complex analytics on structured data, Apache Spark’s DataFrame joins provide a robust solution for handling diverse data integration challenges in modern big data ecosystems.



