
DataFrame is a key abstraction in Spark which represents structured data and allows for easy manipulation and analysis. In this blog post, we’ll explore the various basic DataFrame methods available in Spark and how they can be used for data processing tasks using examples.
Dataset:

There are many DataFrame methods which are subclassified into Transformation and Action based upon the operation performed, you can learn more about these in this blog – Spark RDD Operations (perficient.com). Let’s see some of the basic and regularly used ones. Most of them needs to be imported from spark packages. In the examples the import statements can be found at the top and the ones that we are going to see below are almost SQL functions which are being incorporated on a DataFrame.
Viewing the Data with in the DataFrame:
show:

.show() is to view the data from the dataframe. This can be used when using from the Notebook or when running a job too.
display:
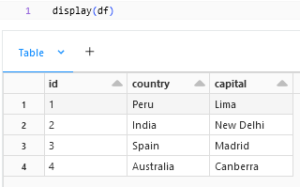
display() can be used when we need to view the data in a notebook this can’t be used when running in a job.
Selecting and Filtering from the DataFrame:
select:
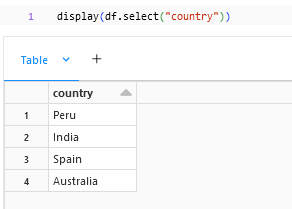
.select() method can be used to select the columns that we need from the dataframe, the above sample shows a selection of one particular column from the dataframe. We can select multiple columns by adding to the select statement like
df.select("country","capital")
head:
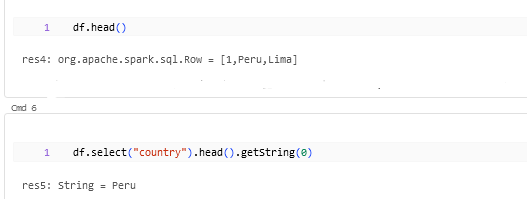
.head() method can be utilized to get the first row from the dataframe which can be used when we need some maximum or minimum values of a particular column.
take:

.take() method provides us with the mentioned rows from the top of the DataFrame.
tail:

.tail() method provides us with the mentioned rows from the bottom of the DataFrame.
filter:
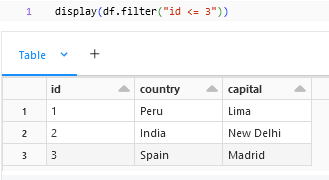
.filter() method can be used to filter the column based upon the column. We can provide the syntax in the sql fashion itself within the filter method.
drop:
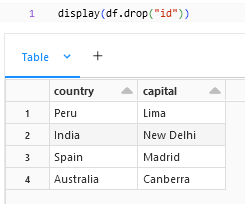
.drop() method can be used to drop a particular column or a set of columns from the dataframe. The syntax for dropping multiple columns would be –
df.drop("column1","column2")
DataFrame Count:
count:
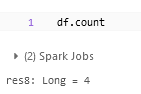
.count method gives us the count of the DataFrame. We can also use select and distinct methods to find the distinct count of a particular column with this syntax
df.select("column_name").distinct.count
Data Manipulation on DataFrame:
withColumn:
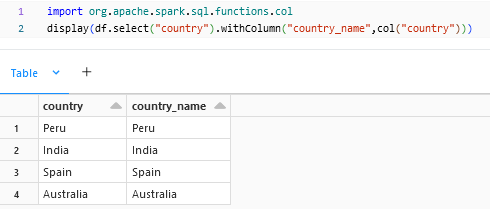

.withColumn() is to add or modify an existing column with a transformation. If the column is existing the transformation will be applied to that column itself. If the column in not present, there will be a new column that will be added at the end of the dataframe with the transformation.
withColumnRenamed:
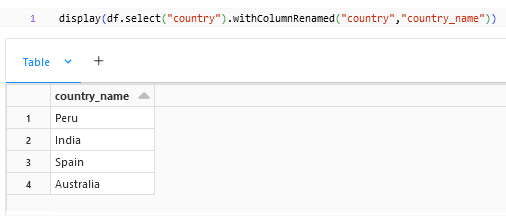
.withColumnRenamed() is to modify the name of the existing column to a new column where the column name needs to be transformed will be given first and the desired output column will be at the last.
upper:
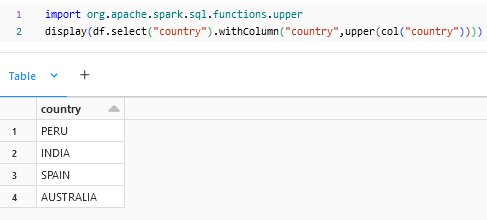
upper() is to change the cases of a column to uppercase.
lower:
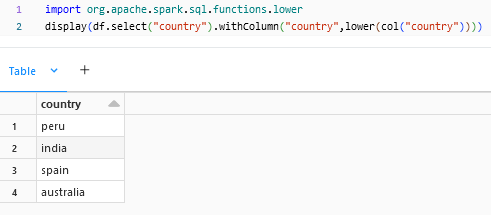
lower() is to change the cases of a column to lowercase.
lit:
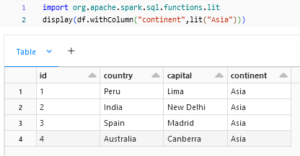
lit() can be used to add or modify a column with hardcoded value.
cast:
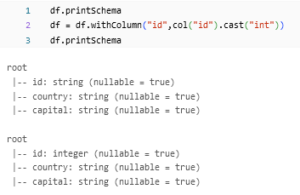
cast() method is to change the datatype of a column from one datatype to another.
na.fill:
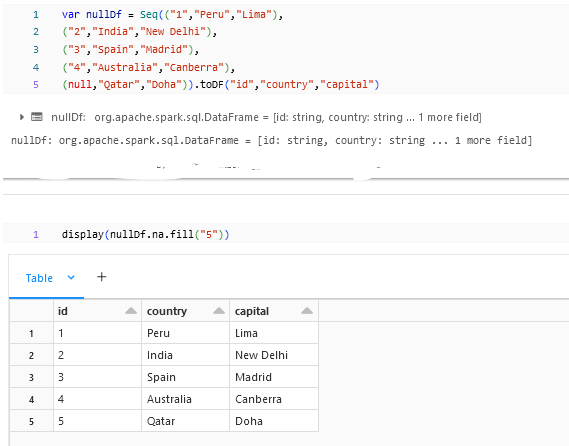
.na.fill(“”) is used to fill the null columns with values.
substring:
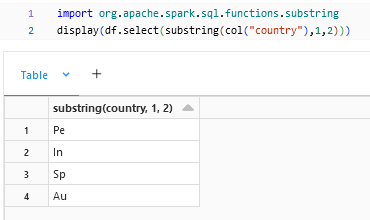
substring() is used to substring a column.
length:
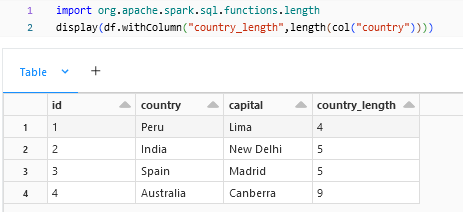
length() is to determine the length of the column.
concat:
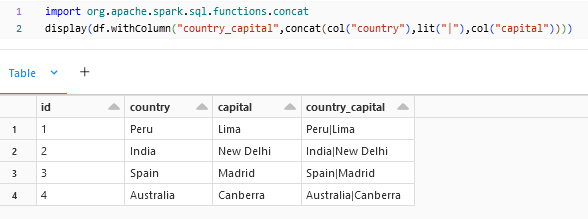
concat() is to add two strings together.
trim:
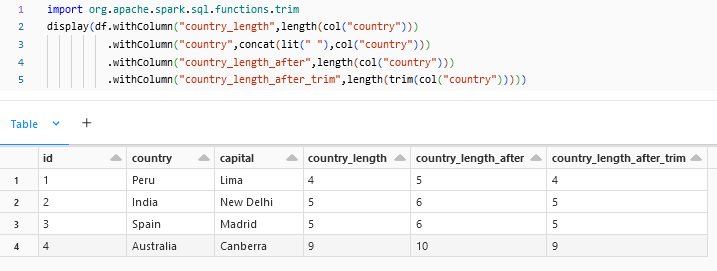
trim() can be used to remove the spaces in the column. If a particular side alone needs to be trimmed then rtrima and ltrim can be used.
Distinct and Union on DataFrame:
union:
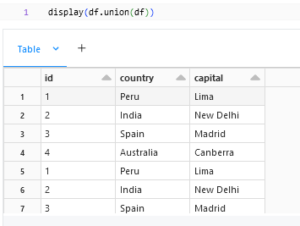
unoin() in DataFrame will give you all the values from both the DataFrame unlike the SQL union where it would result only in distinct values. To get the distinct values we can use. distinct function.
distinct:
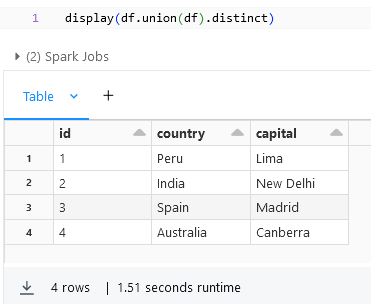
distinct() in DataFrame will return the distinct rows from the dataframe.
Sorting and Ordering on DataFrame:
orderBy:
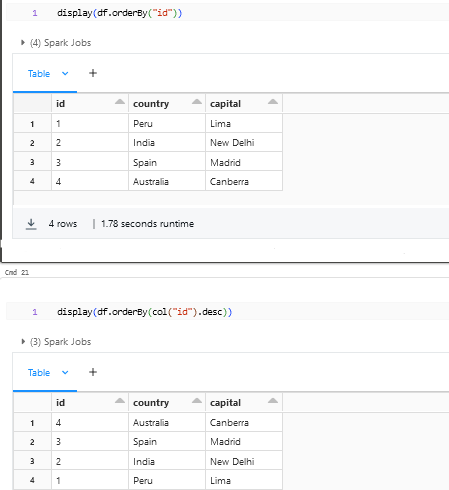
orderBy can be used on a DataFrame to order by on a particular column. By Default, Spark will order by in ascending we can explicitly call out .desc to order by descending.
Optimization and Performance:
repartition:
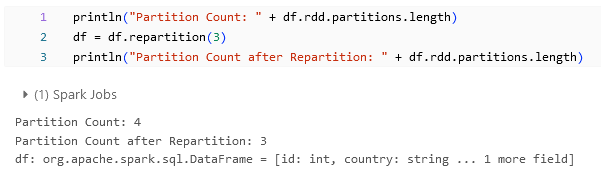
You can use repartition to increase or decrease the number of partitions within the DataFrame. For more information about this, you can find it in the blog titled Spark Partition: An Overview / Blogs / Perficient
There are further optimization methods like persist and cache which you can find more about in this blog: Spark: Persistence Storage Levels / Blogs / Perficient
Joins:
The DataFrames can be joined with one another using the below syntax:
df1.join(df2,df1("col1") == df2("col2"),"inner")
Find more about DataFrame joins in this blog post titled: Spark: Dataframe joins / Blogs / Perficient
References:
Official Spark Documentation: https://spark.apache.org/docs/2.3.0/sql-programming-guide.html
The Databricks DataFrame Guide is available at https://www.databricks.com/spark/getting-started-with-apache-spark/dataframes
In Conclusion this blog provides some basic methods along with its syntax and examples.


